Over the past month or so, we here at Dawn Chorus have been going full steam getting a proposal together for an NIH SBIR. No matter the outcome, we’ve learned a ton doing the background research for this proposal that will really improve the next version of PubTrawlr once we’re ready to deploy it.
The Setting
10:15 p.m. This isn’t really a black metal type of writing session, so I went with a new playlist -> coding mode. Maybe it’s a bit disingenuous since I’m not coding, but it seems chill enough.
10:27 pm. Did you know that the “Gantt” in Gantt chart needed capitalizing? I do now!
10:50. Our grant writer thought this section below was very well written. We agree
The first step in unsupervised ontology generation, then, is concept normalization, or mapping concept-variants to a concept’s standard form. Existing knowledge bases are generally used for such standardization processes; normalization, then, becomes the process of mapping (or linking) entities extracted from text to a standard form in the knowledge base via embeddings or spelling similarity (or some combination of the two).
While existing knowledge bases, including the Unified Medical Language System (UMLS), Medical Subject Headings (MeSH), and the RxNorm ontology (for clinical drugs), will clearly provide a useful starting point in identifying study variables, these thesauri/ontologies have not been explicitly designed with study variables in mind. As such, additional steps will be taken to normalize variable-based concepts that are not included in existing knowledge bases, as well as establish standardized forms. Some of this work will be performed programmatically; however, domain experts will also be invaluable in helping to define the scope and composition of a study variable vocabulary (task 3.1)
10:52. I had to redo a figure to make it more legible. Frankly, it’s one of the best UMAPs I’ve seen in a long time.

11:03. Oh Man, Xtal just came up on the playlist.
11:57. Still working through the personnel section. Let me give a preemptive shoutout to the Alzheimer’s Association, who have prepared a full set of complete supporting documents that are easy to understand and provide sufficient content to enhance certain sections. They rock.
12:34. So, what makes PubTrawlr special? We’ve got three reasons.
- No known website automates the sense-making process. PubTrawlr addresses the intermediate step between the primary literature and consumption of that literature through synthesis, visualizations, and recommendations. This includes NIH-sponsored sites like AlzPed and PubTator
- PubTrawlr is designed for both researchers and the common consumer. The website provides interactive visualizations, recommendations, and simplifications to help people make sense of literature. Other companies target more seasoned, and educated users, which filters out many people who would benefit from the knowledge.
- PubTrawlr’s infrastructure can be dynamically scaled. This means that the number of people who use it can grow without any problems. The machine learning processes it uses mean that the system will improve as more people use it.
12:51. Red Bull really is more effective than Monster.
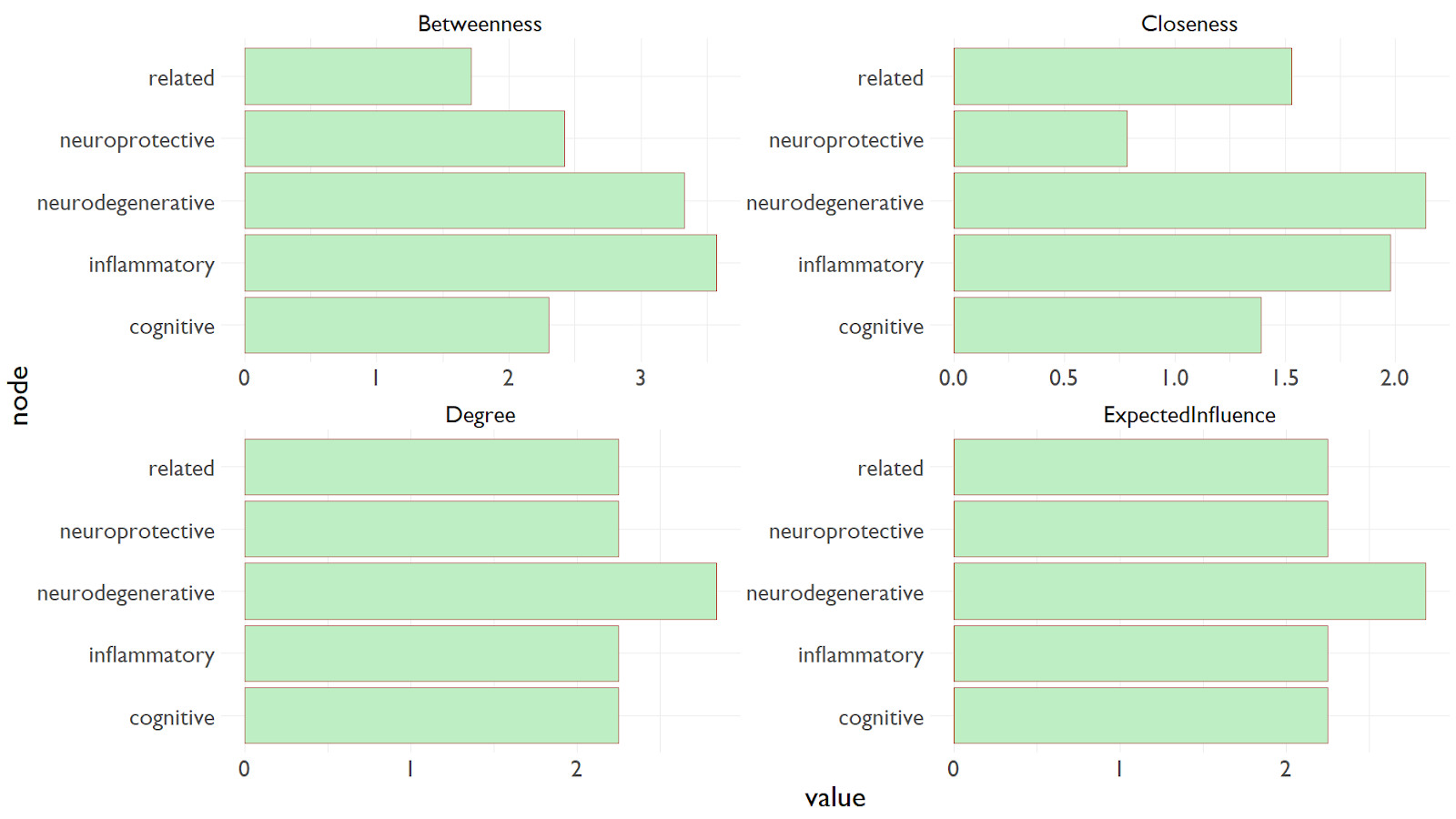
1:54. Okay, so I just spent about an hour rearranging section one. Here’s a new plot that I haven’t shown before. It looks for various characteristics of nodes within a network.
Eh, I think I’m going to have to pick up with this tomorrow morning. But not before we put in some Dalle Robots
