Have you ever wondered how scientists and researchers analyze big amounts of text data? Well, they use a technique called topic modeling! We recently used this method while applying for a grant on Alzheimer’s Disease and Treatment. By looking at around 4,000 articles, we were able to create pictures and graphs that helped us understand the data better. We also improved our algorithm to make it work even better! Join us as we explore the exciting world of topic modeling and learn how it can help us make sense of big chunks of information
What makes a good topic model?
Topic modeling is a way to analyze large amounts of text data and group similar ideas together. The goal is to find the right number of groups, or “topics,” that best capture the main themes in the data.
To determine the optimal number of topics, we need to use a measure called “perplexity.” Perplexity is like a score that tells us how well the topic model is able to predict new data that it hasn’t seen before.
We start by trying different numbers of topics and calculating the perplexity score for each one. We then compare the scores and choose the number of topics that has the lowest perplexity score. This means that the topic model is the most accurate and can predict new data the best.
However, it’s important to remember that choosing the right number of topics is not always easy, and sometimes it requires some trial and error. So, we may need to try a few different numbers of topics and see which one works best for our data.
Overall, determining the optimal number of topics is a process that requires careful consideration of the data and a willingness to experiment until we find the best solution.
Losing interpretability
Sometimes, the perplexity minimizes at a very high number of topics. Having too many topics specified in a topic model can lead to several drawbacks.
Firstly, too many topics can make it difficult to interpret the results. It can be challenging to understand the meaning of each topic, and they may overlap or be too granular to be helpful. This can make it hard to draw meaningful insights from the data.
Secondly, having too many topics can reduce the coherence of the model. The model may struggle to distinguish between similar topics, leading to a loss of clarity and accuracy in the results.
Thirdly, having too many topics can increase the computational complexity and time required to process the data. This can lead to slower processing speeds and higher costs for storage and computing resources.
Lastly, having too many topics may lead to overfitting, where the model becomes too specific to the data used to train it and is not generalizable to new data. This can result in poor predictive performance and decreased utility of the model.
Overall, it is important to balance the number of topics and the quality and interpretability of the results. Careful consideration of the data and the research goals should be taken when deciding on the number of topics to specify in a topic model.
Our Process
We utilized Jason Timm’s PubMedMTK package, which helped expand the Medical Subject Headings (MeSH) vocabulary used in our analysis. This expanded vocabulary may help capture a wider range of concepts and improve the granularity of our topic modeling. By combining these techniques, we hope to achieve a more nuanced understanding of the underlying themes and patterns in our data.
In our case, despite trying to minimize the perplexity score, we consistently ended up with our predetermined maximum number of topics, which was 20.
Evaluating Topics Models
When it comes to topic modeling, it’s essential to evaluate the quality of the models to ensure that they accurately represent the underlying themes and patterns in the data. This requires using a variety of different metrics and techniques to assess the models’ coherence and prominence.
- topic size: Total (weighted) number of tokens per topic
- mean token length: Average number of characters for the top tokens per topic
- document prominence: Number of unique documents where a topic appears
- topic coherence: A measure of how often the top tokens in each topic appear together in the same document
- topic exclusivity: A measure of how unique the top tokens in each topic are compared to the other topics
- time: I also kept track of how long it took each model to run, recognizing that there is a user experience to this element, as well.
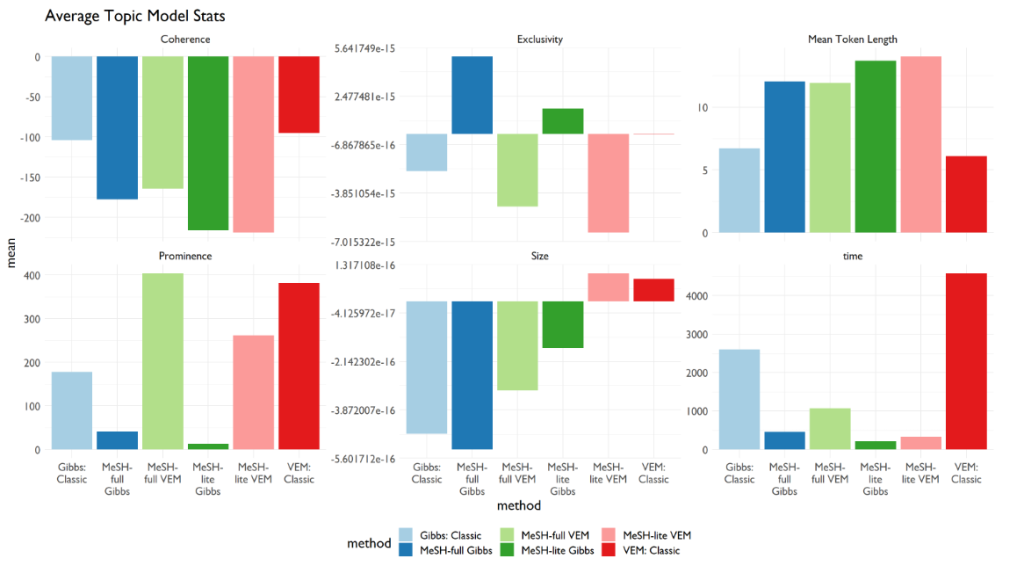
This first image is the summary statistics. I just took the average across all of these quality measures.
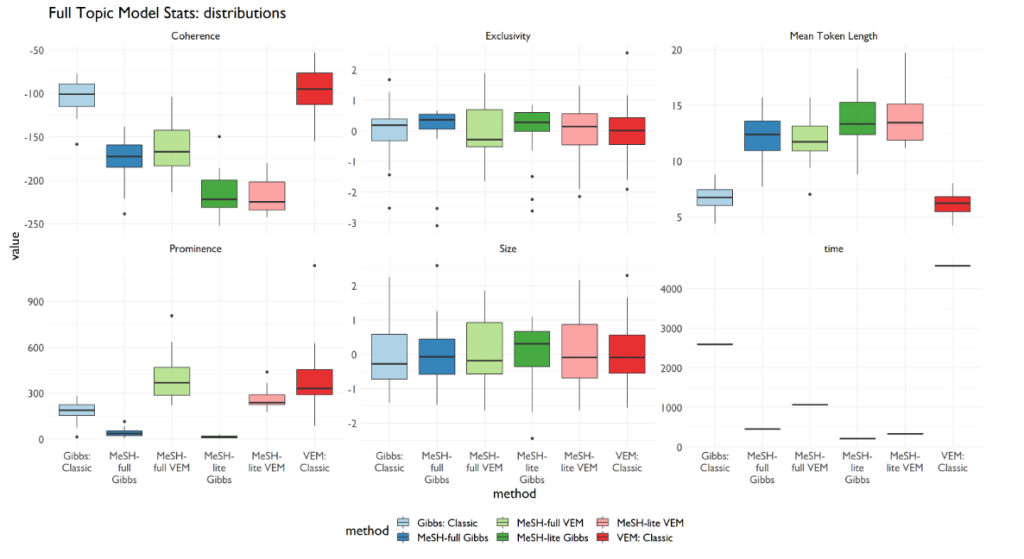
This second images shows the spread of these measures under each model.
What it meant for us
To ensure that our topic model accurately represents the underlying themes and patterns in the data, we need to carefully review the content of the topics. However, in the meantime, we can use exclusivity, time, and coherence as our core metrics to assess the quality of the model.
Exclusivity refers to the extent to which each word in a topic is unique to that topic and does not appear in other topics. This ensures that the topics are distinct and not overlapping, which improves their interpretability.
Time is an important metric to consider because the time it takes to run a topic model can impact the feasibility and scalability of the analysis. Therefore, we need to consider the trade-off between the quality of the model and the time it takes to run it.
Coherence measures the semantic similarity between the words in a topic, which helps to ensure that the topics are meaningful and representative of the underlying themes in the data.
In this particular case, we ended up using the full Medical Subject Headings (MeSH) Vector Equilibrium Model (VEM) to run the topic model when we put it into production. However, this model took around 16 minutes to run, which is a relatively long time. We may be able to reduce the run time by optimizing the parameters or using a different algorithm.
Alternatively, if we value time more than the quality of the model, we could use the full MeSH Gibbs model instead. While this model may not be as accurate as the VEM model, it is faster and may be more practical for certain applications.
Overall, choosing the right metrics and models for a topic modeling analysis requires careful consideration of the data, research goals, and available resources. By balancing these factors, we can develop a topic model that accurately represents the underlying themes and patterns in the data while also being feasible and scalable.
Information in your inbox
Every week, This Week in Public Health pulls and clusters all the publications from about 20 prominent public health journals published in the last seven days. We offer this newsletter for free because we firmly believe that science is a public good and that everyone should have access to the latest research and information.